Sugar Labs/SOM
Kohonen Self Organising Maps

Self Organising Maps (SOMs) can act as 2D spatial summariser visualisations of multidimensional data. In the maps shown here, text distance metrics are generated from the weekly/monthly content on some of the more active mailing lists. Using a geographic like landscape metaphor, the height (colour gradient) indicates features with strong associations to all other features; proximity represents association between specific features (e.g. related words), and label size is a rough guide to basic frequency of a feature. There are many "correct" map layouts for the same set of data, each map generation will usually settle into a slightly different set of local minima, but the associations are no less valid for each. After removing linguistic junk words, and word stemming, the maps currently pick the weeks/months top ~200 features by frequency. Each is a continuous surface and wraps around north/south and east/west (surface of a torus), so if you find an interesting label to one side, remember to check it's neighbours on the opposite side.
What Do They Show?
Well, you could just treat them like tag clouds, showing the top 200 word features used on the list for a given week/month, but the maps also hold spacial information. Word features that appear close together on the map were used closely (on average) in text content from the list. A height metaphor is also used to indicate the features with the strongest mean associations - the map auto centres on the highest pink peak features, these words have the strongest associations with all the rest of the features on the map; word features in the blue and green areas have weaker mean associations relative to the pink highs, but should not be considered negatively as they will often be tightly associated with surrounding neighbours.
It's An Education Project Mailing List (Weekly)
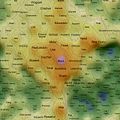
2008 July 5th to 11th
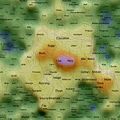
2008 June 28th to July 4th
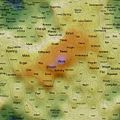
2008 June 21st to 27th
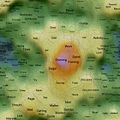
2008 June 14th to 20th
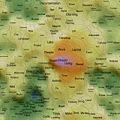
2008 June 7th to 13th
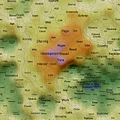
2008 May 31st to June 6th
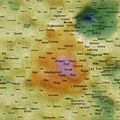
2008 May 24th to 30th
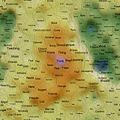
2008 May 17th to 23rd
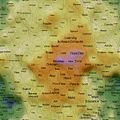
2008 May 10th to 16th

2008 May 1st to 9th










Sugar Mailing List (Monthly)
Future
The mapping algorithms and visualisation style will continue to be refined, details will be posted here on any significant modifications. The code base was originally designed for bulk text documents from a single author, tested on works of literature from Project Gutenberg.